
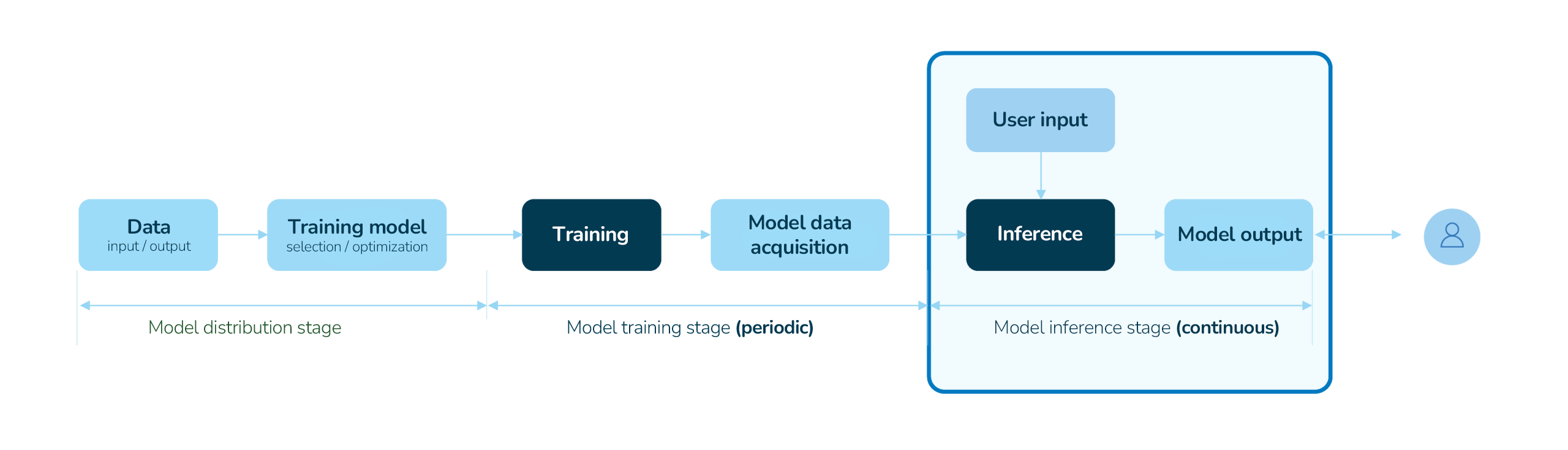









Distributed Inference
Deploy and scale AI anywhere |
AI Gateway
One-stop access to global models |
||
Fabric for AI
High-speed network for AI connectivity |
Bare Metal
On-demand dedicated servers |
|||
Elastic Compute
Scalable virtual servers |
| Cloud Networking | Acceleration | ||
|---|---|---|---|
Cloud Connect
Onramp to public clouds |
Global Accelerator
Improve application performance |
||
Cloud Router
Layer 3 mesh network |
CDN
Global content delivery network |
||
Private Connect
Deploy and scale AI anywhere |
IP Transit |
||
Virtual Edge
Virtual access gateway to private backbone |
IP Transit
High-performance internet access |
||
Edge Colocation
Colocation close to end users |
|||
Custom AI Services
Global AI infrastructure deployments |
Deploy and scale AI anywhere | |
One-stop access to global models | |
High-speed network for AI connectivity |
Bare Metal
On-demand dedicated servers |
|
Elastic Compute
Scalable virtual servers |
| Cloud Networking | |
Cloud Connect
Onramp to public clouds |
|
Cloud Router
Layer 3 mesh network |
|
Private Connect
Deploy and scale AI anywhere |
|
Virtual Edge
Virtual access gateway to private backbone |
|
| Acceleration | |
Global Accelerator
Improve application performance |
|
CDN
Global content delivery network |
|
| Connectivity | |
IP Transit
High-performance internet access |
|
Edge Colocation
Colocation close to end users |
|
Custom AI Services
Global AI infrastructure deployments |

