As part of our commitment to education here at Zenlayer, we hire a few bright students each year as interns to do some networking (both literally and figuratively). One of this year’s interns is Alexander Wang, who is making use of our extensive resources to do a fascinating project about predicting network traffic and flow. The project ties into Zenlayer’s push to devote more resources to research and development, particularly intent-based networking.
Why predict network traffic flow?
“I’m trying to forecast future client activity,” explains Wang. “If we can predict traffic with a reasonable amount of accuracy, we can optimize how we allocate that traffic across our routes and build more redundancy on routes we expect to be heavily trafficked.”
Beyond how many lines or circuits there are on each route, each line also has strict minimum and maximum capacities. If the forecast predicts that one circuit will reach its maximum while another is under-utilized, the network could be optimized by balancing the load more evenly.
Implementation of any network optimization based on these predictions would most likely be via a software-defined network, at least to start, but for now Wang is mostly focused on training, testing, and improving models. To do that, he needs data, and lots of it. Fortunately, Zenlayer has networking traffic data in spades. Wang’s training data set currently consists of 61,000 sets of data inflow and outflow collected over the last eight months.
For both security and privacy reasons Wang can’t see what kind of data is being sent as traffic, only where it came from and where it went. That makes prediction harder for now but the results may be easier to generalize over the long run, since what kinds of data people want to send may change. Netflix, for example, is a huge driver of internet traffic right now that didn’t even exist ten years ago.
What’s the difference between traffic and flow?
Wang is working with both network traffic and flow data. So what’s the difference? Traffic is the total amount of data being sent to or from a port – for example, you might see 10 MB of data (traffic) was sent out at 4 pm. Flow, on the other hand, uses IP addresses to give you a direction. Of that 10 MB of traffic, perhaps 5 MB went to Asia, 3 MB to Africa, and 2 MB to North America. Using flow obviously gives you a lot more information to work with when you’re trying to build a predictive network, but it also means you need to record exponentially more dimensions during data collection.
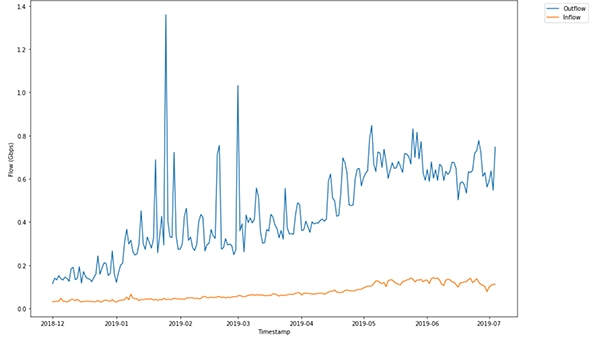
An example of inflow and outflow from Wang’s data set.
How does the model work?
Wang is using “deep learning” to model network traffic. Deep learning uses multiple layers of connected nodes to identify data, create models, or whatever else it is you’re trying to do. The trick, of course, is getting the system to pass input data through layers that result in useful information.
Unfortunately for Wang (but more interesting to study), the latest version of his project involves “unsupervised learning.” It’s not called that because he doesn’t have a manager (he does!) but because there’s no specific answer in the data set. That means the deep learning model doesn’t have a cheat sheet of answers to look at – it needs to come up with its own.
Unsupervised vs supervised learning
The difference between supervised learning and unsupervised learning is whether or not you know the answer you’re looking for. For instance, an AI trained to identify painters by looking at the brushstrokes on paintings is supervised learning because you have a specific solution: this kind of stroke means Monet, that kind of stroke indicates Rembrandt, and so on.
What’s Wang looking for?
Instead of specific answers, Wang is looking for trends and anomalies. An example of a trend would be if he sees data flow from, say, China to India regularly spike on Fridays. That’s a very simple example, however, and easy enough for humans to spot without a complicated model. What Wang is doing is more complex as it looks at the network as a global whole, not just individual connections.
“It’s easy enough to spot patterns in just one or two dimensions – all you do is make a graph. But when you have over a dozen dimensions, it gets much harder to figure out. If a data point is an outlier along three axes but normal along ten others, is that data point an outlier or normal?”
Finding trends
How can you tell if there’s even a trend for the model to find? Wang explains, “The first thing you do is simply look at the data and see if you see something going on, or create a some basic graphs to look for trends. But people are primed to find patterns so that’s just a basic starting point.”
If humans are pattern-prone, how can you tell if your model is working properly and that the predictions it’s making aren’t a coincidence? “That’s what you have two data sets for,” says Wang. “You train on one set and test on the second set. If the model performs well on one but not the other, it’s almost definitely a coincidence or the result of overfitting the training set.” (Overfitting is when the model fits the training set and only the training set – like a three-piece suit that only fits one person and looks terrible on anyone else.)
He goes on to state that outliers throwing off the data in this particular set, however, should be unlikely due to the sample size. “61,000 is a pretty large data set. The odds of having enough outliers to affect the model is relatively small, but I don’t have enough data to model a full year yet. There could be trends or factors specifically in the fall months that my model doesn’t yet take into account.”
The results so far
What’s he found so far? “My model is still rough right now, but I’m seeing some interesting things. The latest version is predicting a lot of growth. That is, while we expect growth, this model is showing even more than we’ve been expecting.”
The model making that prediction is his latest attempt using deep neural networks. Over the course of the project Wang has been using a combination of Kentik’s sophisticated traffic analysis tools and good old-fashioned programming in Python. The current model uses what’s called “long short-term memory” (LSTM). Basically, it looks back at what already happened to predict the future – exactly what he needs to predict network traffic and flow.
What’s next?
When Wang finishes his project he’ll be going back to study Computer Science at the California Institute of Technology, but his model will be greatly expanded on at Zenlayer. Intent-based networking is one of the main areas Zenlayer’s new research and development facility in Hangzhou will be focusing on, and Wang’s models and predictions will be helpful points of reference to set desired network states.
In the long run, if a model can be found that accurately predicts or even approximates traffic and flow, it’ll be a huge boon to not only software-defined networking but infrastructure planning and deployment as well.
For more stories like this, subscribe to our newsletter or follow Zenlayer on LinkedIn, Twitter, or Facebook. For open intern positions, visit Zenlayer Careers.