Welcome to Zenlayer’s technical blog, where you will learn about our latest innovation – Network Load Balancer (NLB). NLB operates at the transport layer (layer 4) and is designed to enhance network reliability, operational efficiency, and the overall capabilities of our hyperconnected cloud infrastructure.
Understanding the role of NLB
In the world of global edge networks, traditional networking devices like routers and switches operate at lower layers (layer 2 and layer 3), focusing on static packet forwarding. While reliable and fast, they lack the intelligence needed to optimize network performance. On the other hand, servers handle higher layers, executing application logic. However, they often face performance bottlenecks and lower availability.
This is where our NLB steps in. Operating at the packet header and layer 4 protocol level, it dynamically forwards packets based on application state. This intelligent routing bridges the gap between servers and networking devices, optimizing both reliability and operational efficiency.
The significance of NLB
The need for NLB arises from various factors, such as hardware/software failure rates that impact server availability. Our NLB mitigates risks associated with issues like buggy firmware, design flaws in servers, memory or power module failures, and bad optical fibers. It also facilitates server movements for maintenance or business needs with features like connection training.
Technical breakdown: leveraging DPVS for high performance
Our NLB leverages DPVS — a high-performance layer-4 load balancer based on DPDK (Data Plane Development Kit). We chose DPVS for the following reasons:
- High Packet Processing Capabilities: DPVS enables a staggering 20 million ingress packets per second (PPS) for a single point of presence (PoP), ensuring lightning-fast packet forwarding.
- High Availability: Comparable to networking equipment, DPVS guarantees exceptional availability crucial for mission-critical cloud services.
- Ease of Deployment: DPVS is designed for seamless deployment across our expansive global edge network, supporting our agile operational model.
High packet processing capabilities
DPVS addresses the issue of low software forwarding performance, a problem often associated with traditional kernel-based forwarding solutions. While these solutions offer rich functionality and stability, they fall short in performance for real-time intensive applications like load balancers, rendering them unsuitable for production use.
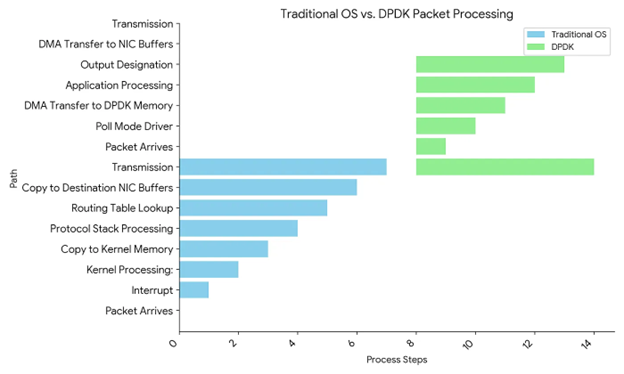
To illustrate, the traditional Linux network forwarding path follows these steps:
- Packets arrive at the network interface card (NIC).
- The NIC generates an interruption to notify the operating system (OS).
- The OS responds by copying the packet into the kernel memory.
- The kernel protocol stack processes the packet, including routing table lookups.
- The OS copies the processed packet back to the NIC buffer.
- The NIC is notified to transmit the packet.
In contrast, DPDK employs an entirely different, but more efficient approach:
- DPDK uses a polling mechanism where dedicated CPUs continuously check if there are new packets arriving at the NIC, avoiding interruptions.
- Through DMA mechanisms, packets are directly transferred to user-space memory pre-allocated by DPDK, eliminating the need for kernel copying, known as zero copy.
- DPDK utilizes Huge Pages to reduce memory management overhead, including reducing cache misses and TLB buffer pressure.
- DPDK implements a simpler protocol stack compared to the kernel.
- DPDK utilizes lockless ring buffers, batch reception (RX)/transmission (TX), RX steering, CPU affinity, and other techniques to enhance performance. We’ll deep dive into the importance of CPU affinity optimization later in the blog.
The following diagram visualizes the similarities and differences in the packet forwarding steps between the kernel and DPDK.
DPVS guarantees high availability
Using our popular node Jakarta (JKT) in Southeast Asia as an example, within the last 15 days, an 8-way Equal-Cost Multi-Path (ECMP) cluster hasn’t dropped any packets. The average inbound packet rate for the cluster is 3M packets per second (pps). Over 15 days, the cluster has forwarded 3,888,000,000,000 (i.e. 3.888 trillion) packets with zero drop.
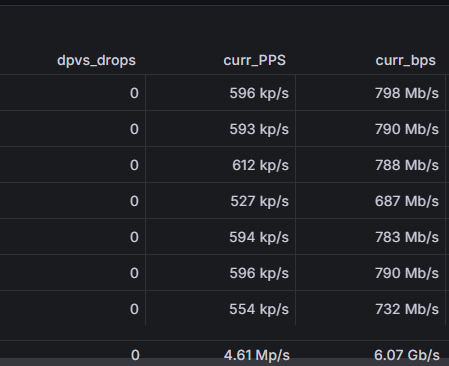
DPVS is designed for easy deployment
During the actual deployment of DPVS, several factors need to be considered such as configuring CPU affinity, which needs to be adjusted according to the specific characteristics of the CPU. Otherwise, packet forwarding may be affected by other processes, causing intermittent random packet loss.
Taking Intel CPUs as an example, a DPDK program only uses CPU cores from one NUMA node. If hyper-threading is enabled, only one logical core within each physical core is used, and the other logical core is not utilized. You can use cpu_layout.py to view the CPU core distribution. The 1GB huge pages memory is also allocated on this NUMA node. All CPUs used by the program, including control and forwarding cores, need to be isolated from the system.
The traditional isolcpus isolation method is no longer effective on Ubuntu 22.04, so systemd must be used. For example, with a dual-socket Xeon Gold 6226R system, if DPVS uses 1 control core + 8 forwarding cores + 1 KNI core, a new file named dpvs.slice should be created with the following content:
[Unit]
Description=Slice for DPVS
Before=slices.target[Slice]
AllowedCPUs=16-25
In the dpvs.service file, add the following:
[Service]
Slice=dpvs.slice
To set the CPUs available for other processes (e.g. monitoring program like Prometheus/Zabbix or control plane agent), use the following commands:
systemctl set-property system.slice AllowedCPUs=0-15,26-31,32-47,58-63
systemctl set-property user.slice AllowedCPUs=0-15,26-31,32-47,58-63
DPVS is more cost-effective
Unlike commercial load balancers like the F5, DPVS operates at the cost level of x86 servers, ensuring optimal performance without breaking the bank.
Comparison with other load balancer solutions
Our decision to adopt DPVS over other load balancer solutions was driven by rigorous performance and feature comparisons:
- Kernel-based Solutions (e.g., LVS): These solutions, while stable and feature-rich, exhibit medium to low performance, with packet loss becoming evident beyond 1.5 million PPS in production. They also require excessive server resources, rendering them less cost-effective.
- Pure L3-based Solutions (e.g., ECMP): ECMP solutions are vulnerable to active set changes, and face challenges with scalability and manageability, particularly when backend configurations exceed 20,000 nodes.
- XDP-based Solutions (e.g., Meta’s Katran): XDP-based solutions, while offered as a service, often fall short in terms of feature set and customization, limiting their suitability for our diverse requirements.
- Commercial Products (e.g., F5 BIG-IP): Commercial products like F5 BIG-IP, while feature-rich, are cost-prohibitive for widespread deployment across our extensive network of 300+ PoPs.
Our development journey and commitment to excellence
Behind the scenes, our team has been diligently refining our NLB. Addressing production challenges, we’ve tackled bugs and introduced critical features like fragmentation reassembly and TCP_SLOPPY to optimize performance:
- Bug fixes
In the process of refining our NLB, we encountered some situations not usually found in upstream open-source projects due to differences in business environment requirements between us and the authors of DPVS. For instance, we encountered a VLAN interface deletion hang. When deleting a VLAN interface, the underlying KNI interface needs to be released. However, if the KNI interface is still asynchronously receiving packets and lacks proper locking, it can lead to underlying data anomalies and a deadlock. Additionally, we’ve identified some IPv6 related bugs that occur when adding and deleting IPv6 addresses, which cause the NIC multicast allow-list to be deleted, leading to network interruption. - Feature enhancements
Typically, a TCP SYN packet is considered the start of a new connection. However, when TCP_SLOPPY is enabled, an ACK packet can also be recognized as the start of a new connection. After the ACK packet is validated, it undergoes load balancing by selecting backend nodes through MH (Maglev Hash). MH selects backend nodes based on the source IP or source port. In situations where the backend node remains unchanged, it will continue to select the same backend node. This ensures that if one director fails and the packet is redirected to another director, it will still be routed to the same backend node.By utilizing the MH algorithm, we’ve eliminated the need for complex director connection synchronization. Additionally, by combining this with the network switch’s ECMP, we’ve been able to:
-
- Implement and active-active mode.
- Add or remove directors without causing any traffic interruption.
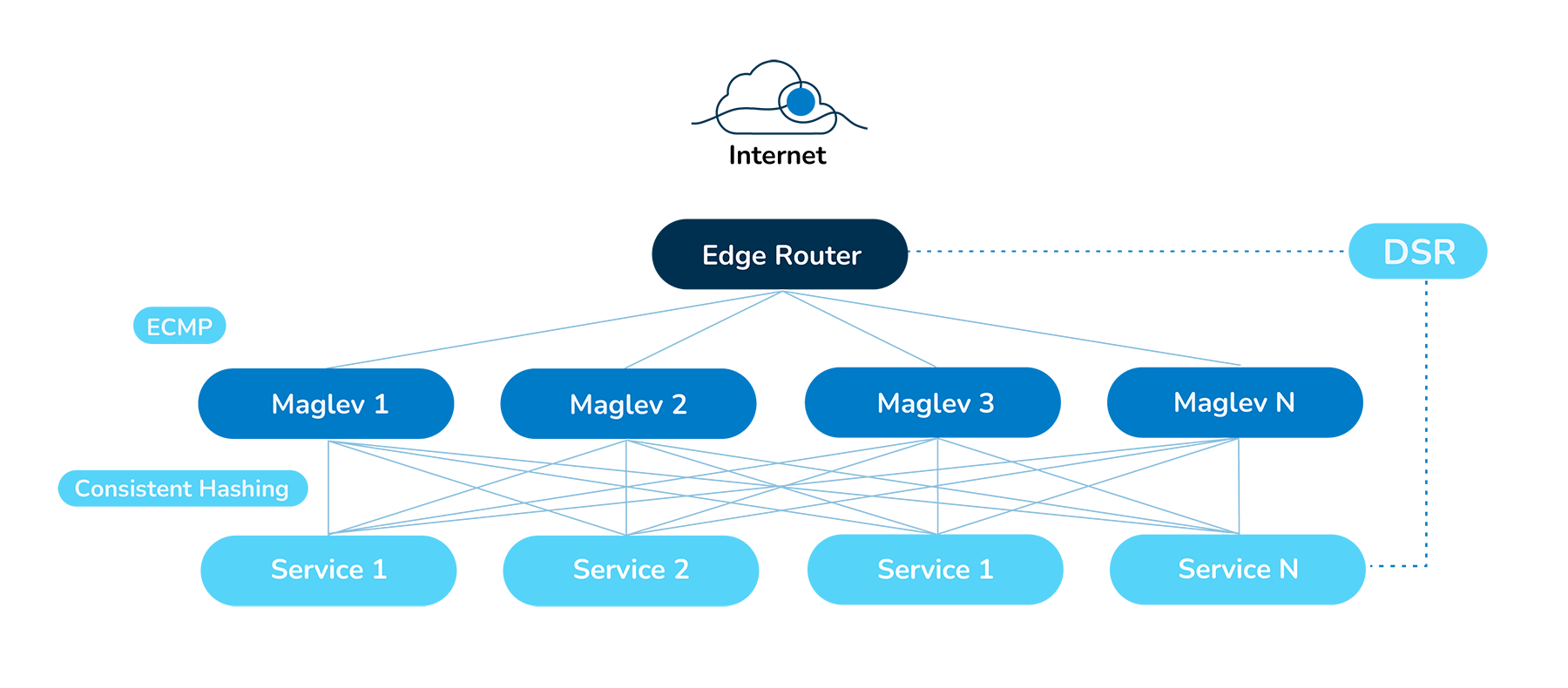
- Built on bare metal: We’ve leveraged our robust bare metal infrastructure for seamless deployment, ensuring optimal performance and reliability.
- Dogfooding for deployment facilitation: By using our own services extensively, we’ve streamlined deployment processes and enhanced user experience. We’ve implemented a robust control plane by doing the following:
-
- Combining the benefits of our bare metal BGP feature, which allows customers to advertise their own IP/ASN to our uplink IP transit carriers. This enables customers to bring their own IP (BYOP), allowing control plane services to focus on managing the DPVS cluster and speeding up the development and deployment process.
- We’ve implemented API-based dynamic configuration, including creating and modifying VIP, Listener Port, Health Checker, etc., which can take effect within seconds.
- We’ve introduced a multi-level and flexible configuration check mechanism. It provides three hierarchical inspection modes for NLB nodes, VLANs, and NLB instance resources, and verifies all NLB configurations before introducing network traffic, ensuring the correctness of the configuration and network connectivity.
- The edge control plane of the NLB node is configured with a local cache policy to tolerate the offline service of the central control plane.
We’ve also made significant investments in monitoring. Our real-time monitoring and alert system spans across 160 global data centers, ensuring comprehensive coverage. The system collects 760K metrics per second and processes 65 billion data records daily.

Results and future plans
Our NLB is currently deployed on 40% of our edge nodes with plans for full deployment across all nodes imminent. This service has been key in catering to our most demanding customers, handling up to 50 million packets per second (pps) and scaling globally to 1,000 million pps during network traffic spikes.
Looking ahead, we’re committed to leveraging the latest hardware technologies, like AMD Zen4 CPUs and Intel IPU, to further enhance our NLB capabilities. We will continue to invest in our global network infrastructure to offer regional NLB services and expand our reach.
Final thoughts
Zenlayer’s NLB is more than just a technical solution—it’s a testament to our commitment to innovation and customer-centric development. By marrying advanced software with raw hardware and maintaining a relentless focus on research and development, we’re delivering unique value to our hyperconnected cloud customers.
Join us on this journey of building exceptional cloud networking services. Our dedicated team, boasting diverse technical abilities, is key to overcoming challenges and creating value for our customers.
Stay tuned for future updates and insights into our NLB service and other technical endeavors!